核心类库D3:集合框架、Collection集合、List集合、泛型机制、Queue集合、Set集合、Map集合
1.集合框架
1.1 复习
- 当需要在程序中记录单个数据内容时,则声明一个变量记录即可;
- 当需要在程序中记录多个类型相同的数据内容时,则声明一个一维数组记录即可;
- 当需要在程序中记录多个类型不同的数据内容时,则构造一个对象记录即可;
- 当需要在程序中记录多个类型相同的对象时,则声明一个对象数组记录即可;
- 当需要在程序中记录多个类型不同的对象时,则声明一个集合记录即可;
1.2 框架结构
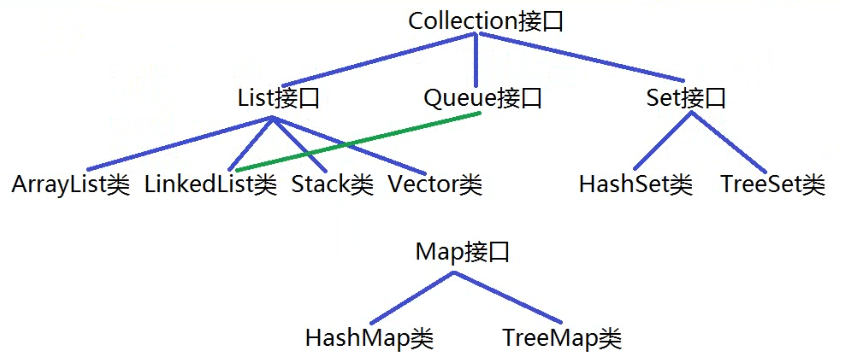
- 在Java语言中用于描述集合的顶层框架:Collection集合 和 Map集合。
- 其中Collection集合中存取元素的基本单位是:单个元素。
- 其中Map集合中存取元素的基本单位是:单对元素。
- 在以后的开发中很少直接使用Collection集合,而是更多地使用Collection集合的子集合:List集合、Queue集合以及Set集合。
2.Collection集合(java.util包)
2.1 常用的方法(练熟、记住)
- boolean add(E e):向集合里添加对象,成功返回true,失败返回false
当打印集合中的所有元素时,本质上就是调用各个元素对应类中的toString - bollean contains(Object obj):查找集合中有没有参数传入的对象,有则返回true,没有则返回false
- contains方法的工作原理是
o==null ? e==null : o.equals(e) - 若参数对象为空,则只需要查找当前集合中是否有元素为null
- 若参数对象不为空,则使用参数对象调用equals方法与集合中元素依次比较
- 当Student类中没有重写equals方法时,调用继承的版本,比较地址,返回false
- 当Student类中重写equals方法后,调用重写的版本,比较内容,返回true
- Java官方写好的类Java官方已经重写了equals,所以比较的是内容,而我们自己写的类必须重写equals才能比较内容
- contains方法的工作原理是
- bollean remove(Object obj):删除成功返回true,失败返回false
- void clear():全删,清空
- int size():返回集合中元素的个数
没有声明,直接用的变量肯定是成员变量
3.List集合(重中之重)
3.1 基本概念
- java.util.List集合是Collection集合的子集合,元素
有先后放入次序并且可以重复 - 该集合的主要实现类有:ArrayList类、LinkedList类、Stack类以及Vector类。
- 其中ArrayList类的底层是采用
数组进行数据管理的,访问方便但增删不方便。 - 其中LinkedList类的底层是采用
链表进行数据管理的,增删方便但访问不方便。 - 其中Stack类的底层是采用
数组进行数据管理的,该类主要用于描述具有后进先出特性的数据结构,叫做栈(last in first out 简称为:LIFO)。 - 其中Vector类的底层是采用
数组进行数据管理的,与ArrayList类相比属于早期提供的类,支持线程安全,但效率比较低,以后的开发中首选ArrayList类。
3.2 常用的方法
- void add(int index,E element):向集合中指定位置添加元素
- 有new的是放到堆区里,没有new的是放到常量池里
- 集合里之所以能放各种类型的对象,是因为这些对象都被看做Object类型放入的,取出来的类型也是Object类型
- boolean addAll(int index,Collection<?extends E>c):向集合中添加所有元素
- E get(int index):从集合中获取指定位置元素
- 你的数据类型是什么类型就要强转成什么类型,否则就会出现类型转换异常
- E set(int index,E element):修改指定位置的元素,返回被修改的元素
- E remove(int index):删除指定位置的元素,返回被删除的元素
- subList(1,list):获取List子集合,子集和原List共用一个地址
4.泛型机制(重点)
4.1 基本概念
- 通常情况下集合中可以存放不同类型的对象,是因为集合将这些对象全部看做Object类型放入的,当从集合中取出元素时也是Object类型的,为了表达该元素最真实的数据类型则需要进行强制类型转换,此时可能引发类型转换异常。
- 为了避免上述错误的发生,从jdk1.5开始提出泛型机制,也就是在集合名称的右侧使用<数据类型>的方式明确要求该集合中可以存放元素的类型,若放入其他类型的元素则编译报错,如:
`List
lt1 = new LinkedList ();` - 使用泛型机制就不用强转了
- 菱形特性:后面那个
里什么都没有`<>`,jdk1.7开始 - 类名或接口名后面带
<E>的表示支持泛型
4.2 泛型的本质
- 泛型的本质就是参数化类型,也就是让数据类型作为参数传递
- 其中集合中E作为形参负责占位,当使用集合时<>中的数据类型作为实参给E进行赋值操作,从而使得集合中所有的E都被替换为实参指定的类型。
- 由于实参的传递支持各种各样广泛的类型,因此得名为”泛型机制”
// 其中i表示形式参数,负责占位 其中E表示形式参数,负责占位 // int i = 2; E = String; // int i = 5; E = Student; public void show(int i) { public class List<E> { ... ... } } // 其中2表示实际参数,用于给形参初始化 // 其中String表示实际参数 show(2); List<String> lt1 = ...; show(5); List<Student> lt2 = ...;
5.Queue集合(重点)
5.1 基本概念
- java.util.Queue集合是Collection集合的子集合,与List集合属于平级关系。
- 该集合主要用于描述具有
先进先出特征的数据结构,叫做队列(first in first out,FIFO)。 - 该集合的主要实现类有:LinkedList类,该类在增删方面有优势。
5.2 常用的方法
- boolean offer(E e):将一个对象添加至队尾,若添加成功则返回true
- E poll():从队首删除并返回一个元素
- E peek():返回队首的元素(但并不删除)
5.3 练习:
准备一个Queue集合,将数据11、22、33、44、55进行依次入队操作并打印,然后查看队首元素值并打印出来,再将队列中的所有元素依次出队并打印,最后打印队列中最终的所有元素。
6.Set集合(重点)
6.1 基本概念
- java.util.Set集合是Collection集合的子集合,与List集合以及Queue集合属于平级
- 该集合与List集合相比元素没有先后放入次序,并且不允许有重复的元素。
- 该集合的主要实现类有:HashSet类 和 TreeSet类。
- 其中HashSet类的底层是采用哈希表进行数据管理的。
- 其中TreeSet类的底层是采用二叉树进行数据管理的。
6.2 常用的方法
- 参考Collection集合中的方法即可;
- Iterator
iterator() - 用于获取当前集合中的迭代器对象,可以取出每个元素。 - 其中Iterator是个接口类型,该接口的常用方法有:
- boolean hasNext() - 用于判断集合中是否有可以访问的元素。
- E next() - 用于获取集合中一个元素并指向下一个元素。
- void remove() - 用于删除迭代器获取到的元素。
- 注意:当使用迭代器迭代集合中的所有元素时,若使用集合中的remove方法来删除元素,则会出现ConcurrentModificationException并发修改异常,以后的开发中应该使用迭代器的remove方法来删除元素。
- 思考:为啥要保证hashCode方法和equals方法的一致性???
解析:只要equals方法相等则要求hashCode相同,而哈希码值相同时使用同一个哈希算法算出来的索引位置就相同,从而避免同一个元素所在索引位置不同引发的错误。
6.3 使用迭代器来访问集合中的所有元素[one, two]
- 调用成员方法获取迭代器对象
Iterator<String> it = s1.iterator(); - 使用迭代器对象获取每个元素并打印
//判断该迭代器指向的集合中是否拥有可以迭代/遍历的元素 System.out.println(it.hasNext()); // true //获取一个元素并指向下一个位置 //与toString方法相比取出的是单个元素,更加灵活 System.out.println("获取到的元素是:" + it.next()); //one while(it.hasNext()) { System.out.println("获取到的元素是:" + it.next()); }
6.4 增强版的for循环遍历(for each结构)
- 语法格式
for(元素类型 变量名 : 数组/集合的名称) { 循环体; } -
执行流程
不断地从数组或集合中取出一个元素赋值给变量后执行循环体,直到所有元素取完为止 - 总结:
- 遍历Set集合中所有元素的方式有3种:toString方法、for each结构、迭代器
- 遍历List集合中所有元素的方式有4种:除了上述3种外还有get方法。
7.Map集合(重点)
7.1 基本概念
- java.util.Map<K,V>集合中存取元素的基本单位是:单对元素,具体类型参数如下:
K - 此映射所维护的键(Key)的类型
V - 映射值(Value)的类型 - 该集合中不能包含重复的键;每个键最多只能映射到一个值。
- 该集合的主要实现类有:HashMap类 和 TreeMap类。
- 其中HashMap类的底层是采用哈希表进行数据管理的。
- 其中TreeMap类的底层是采用二叉树进行数据管理的。
7.2 常用的方法
- V put(K key,V value);将key-value对存入Map,若集合中已经包含该key,则替换该Key所对应的Value,返回值为该Key原来所对应的Value,若没有则返回null(增加和修改)
- V get(Object key);返回与参数Key所对应的Value对象,如果不存在则返回null(修改)
- boolean containsKey(K Key);查找键是否存在,存在即返回true,不存在即返回false
- boolean containsValue(V Value);查找数据是否存在,存在即返回true,不存在即返回false
- V remove(K Key);删除元素,不存在该元素则返回null,存在该元素则返回该元素本身
7.3 遍历Map集合
- 方式1:toString方法
- 方式2:enTrySet方法,以键值对为基本单位进行转换
Set<Map.Entry<Integer,String>> s1 = m1.entrySet(); for(Map.Entry<Integer,String> me : s1) { System.out.println(me); me.getKey(); me.getValue(); } - 方式3:keySet方法,以键为基本单位进行转换(常用)
Set<Integer> s2 = m1.keySet(); for(Integer it : s2){ System.out.println(it+"="+m1.get(in)); }
7.4 Map集合的实际应用
- Map集合是面向对象
查询优化的数据结构,在大数据量情况下有着优良的查询性能,经常用于根据key检索value的业务场景 - 用户登陆数据缓冲:用户名是key,用户对象是value,在登录验证的时候根据用户名快速查询用户信息
- 登录会话保持状态:在网站编程中,用户会话状态保持经常采用Map存储,可以快速在数以万计的信息中快速确定用户是否已经登录
注意
- 一维数组的容量就是初始容量16
- 加载因子75%,
16*75%=12,就是索引下标位置里面,当有12个下标位置已经挂满了元素时,可以认为这个数组即将挂满,底层就会自动扩容
对比数组
| 数组 | 集合 | |
| 是否连续 | 连续 | 不连续 |
| 数据内容类型是否相同 | 类型相同 | 可以不同 |
| 是否支持下标访问 | 支持 | 部分支持 |
| 增删是否 移动大量元素 | 可能会移动 | 可以不移动 |
| 长度大小是否可变 | 不可 | 可以 |
| 数据内容类型 | 基本和引用 | 引用(基本类型可通过包装类转换) |
作业:
- 复习和练习List集合的常用方法并进行整理。
- 查询java.util.Stack类,实现将11 22 33 44 55依次入栈再出栈。
- push():入栈
- peek():查栈顶元素
- pop():出栈
- 提示用户按照指定的格式输入生日信息,计算距离1970年1月1日的天数并打印出来
- 复习和总结集合的所有内容,重点掌握Queue集合和Stack集合的代码。
- 准备一个HashSet集合,实现生成10个1~20之间不重复的随机数放入集合并打印。
集合中只能放引用类型数据 - 声明一个List集合放入11、22、33、44、55,分别使用4种方式遍历。
- 准备一个HashMap集合,统计字符串”123,456,789,123,456”中每个数字字符串出现的次数并打印出来。